Binary Classification Example With Python
You can learn a lot by beginning with a simple example, solving a binary classification task with python.
In addition, python may be the easiest programming language to use for building up an understanding of machine learning.
Further, we’ll delve into cancer dataset downloading and preprocessing, finding optimal classifier model and finding optimal hyperparameters for it.
Solving binary classification for cancer type with python
First thing we’ll need is to import all the necessary libraries, such as kaggle, pandas, numpy and sklearn.
Since we’re also going to use other modules, for learning which model would be most optimal, we’ll import them later.
import pandas as pd
import numpy as np
from kaggle.api.kaggle_api_extended import KaggleApi
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, LabelEncoder
from sklearn.model_selection import train_test_splitNext, we need to connect and authenticate with Kaggle API, so we’ll be able to download the dataset.
# authenticate connection with Kaggle API
api = KaggleApi()
api.authenticate()And after that, we’ll go on and download and preprocess it using pandas and other sklearn modules.
# download dataset from https://www.kaggle.com/datasets/erdemtaha/cancer-data
api.dataset_download_file(
'erdemtaha/cancer-data',
file_name='Cancer_Data.csv',
path='datasets'
)
# load and preprocess dataset
df = pd.read_csv('datasets/Cancer_Data.csv')
print(df)
target = 'diagnosis'
target_data = df[target]
input_data = df.drop([target, 'id'], axis=1)
# transform string into numbers for labels
encoder = LabelEncoder()
target_data = encoder.fit_transform(target_data)
X_train, X_test, y_train, y_test = train_test_split(
input_data, target_data,
train_size=0.8,
random_state=42,
stratify=target_data
)
# imputer will fill missing values
# scaler will center and scale the data using (x - u) / s formula,
# where x is training sample, u is the mean of training samples and s is standard deviation
pipeline = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
X_train = pipeline.fit_transform(X_train)
X_test = pipeline.transform(X_test)Okay, now we have our dataset ready for training machine learning models.
In the next step, we’re going to use a library lazypredict in order to get performance metrics for various different models. Additionally, as you’ll be able to see, the following metrics indicate performance for this specific dataset.
# find most optimal model for classification problem at hand
from lazypredict.Supervised import LazyClassifier
classifier = LazyClassifier(
verbose=0,
ignore_warnings=True,
custom_metric=None
)
models, predictions = classifier.fit(X_train, X_test, y_train, y_test)
print(models)And if you run the script at this point, you’ll get a table of different models and their training metrics.
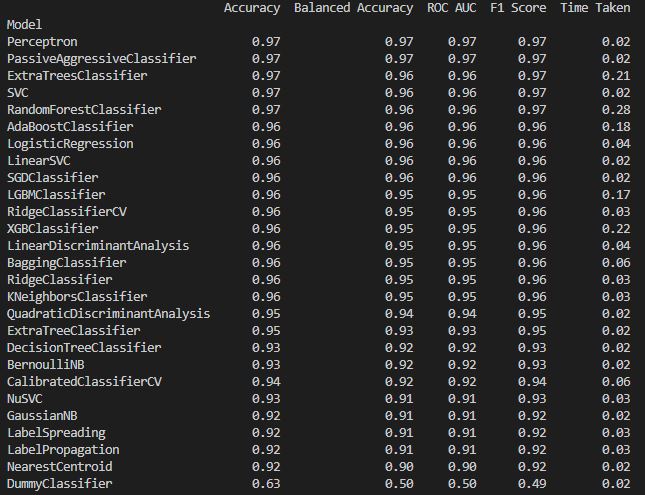
The algorithm also sorts the models from best to worst based on performance.
Furthermore, as you can see from the table, the ideal model for our binary classification problem is perceptron.
Our next step is to find optimal hyperparameters for perceptron model, which we’re going to do using grid search technique.
# find optimal hyperparameters for the model
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.linear_model import Perceptron
model = Perceptron()
params = {
'penalty': ['l2', 'l1', 'elasticnet', None],
'l1_ratio': list(np.linspace(0.0, 1.0, num=10)),
'fit_intercept': [True, False],
'max_iter': list(range(100, 1600, 100)),
'tol': [1e-3, 1e-4, 1e-5, 1e-6]
}
grid = GridSearchCV(model, params, scoring='precision', cv=5, verbose=1, n_jobs=-1)
grid.fit(X_train, y_train)
y_predict = grid.predict(X_test)
print(grid.best_score_)
print(grid.best_params_)
print(classification_report(y_test, y_predict))We can go ahead and run the script again, which will print out results from best performing combination of hyperparameters.
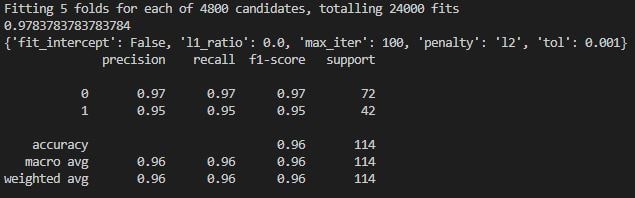
Now we have all the data we need to make an optimal model, including its hyperparameters , to solve this binary classification task. This part may also take a few moments to complete.
# train the model with optimal hyperparameters and print out its accuracy
model = Perceptron(fit_intercept=False, l1_ratio=0.0, max_iter=100, penalty='l2', tol=0.001)
model.fit(X_train, y_train)
print('Model accuracy:', model.score(X_test, y_test))And finally, this will print out our models accuracy, which indicates that it’s 96.5%.
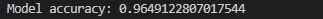
Conclusion
To conclude, this example of binary classification shows how to create an optimal model with lazypredict and grid search.
I hope this guide helped you gain a better understanding of how to make a binary classification model with python.