
Upgrading Movie Recommendation System – Part 2
This post is a follow up on a movie recommendation system tutorial, where we covered how to retrieve recommended movies. Furthermore, we’ll upgrade that system by adding a ranking stage.
In general, these sort of systems work in 2 stages, retrieval and ranking. While retrieval stage can already act as a recommender by itself, we can make it even better with ranking. Therefore, we’re going to focus on this upgrade in this tutorial.
Much of the code here will be the same or similar to what we already did in the first part. But it is necessary as it will make this algorithm whole.
Prerequisites & data preparation
As in previous tutorial, we’ll be working with movielens dataset, which we can import from Tensorflow datasets. But before, we start with the dataset, we need to import all the necessary libraries and tools first.
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrsIf you checked out Part 1 of this guide, you’ll be able to see that we’ll use the same tools here, without any new additions.
In the following step, we’ll import the dataset and preprocess it. Furthermore, we’ll be able to use it to train both retrieval and ranking models. This part is also pretty much the same as in part 1, with a minor addition of user ratings data.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"user_rating": x["user_rating"]
})
movies = movies.map(lambda x: x["movie_title"])
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
movie_titles = ratings.batch(1_000_000).map(lambda x: x["movie_title"])
user_ids = ratings.batch(1_000_000).map(lambda x: x["user_id"])
unique_movie_titles = np.unique(np.concatenate(list(movie_titles)))
unique_user_ids = np.unique(np.concatenate(list(user_ids)))Recommendation system stage 1: Retrieval
Now that we have our data ready, we can start with the part we already worked on previous guide. However, I did implement a few changes, which will help optimize the code further along.
One obvious change that I made is that I defined a function, which will build the embeddings model. Therefore, we can use it to define user and movies embeddings models just by providing it their respective vocabulary.
embedding_dimension = 32
def build_embedding(vocab, embedding_dimension):
model = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=vocab, mask_token=None
),
tf.keras.layers.Embedding(len(vocab) + 1, embedding_dimension)
])
return model
user_model = build_embedding(unique_user_ids, embedding_dimension)
movie_model = build_embedding(unique_movie_titles, embedding_dimension)The function takes 2 arguments, which are the vocabulary as we already mentioned, and the embedding dimension. For simplicity, we define embedding dimension globally, so we can use it for both models.
Next, we need to define task object for the retrieval model, which is essentially a bundle of loss function and metrics.
retrieval_metrics = tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(movie_model)
)
retrieval_task = tfrs.tasks.Retrieval(
metrics=retrieval_metrics
)Okay, now we’re ready to define the retrieval model, compile, and train it.
class RetrievalModel(tfrs.models.Model):
def __init__(self, user_model, movie_model):
super().__init__()
self.movie_model: tf.keras.Model = movie_model
self.user_model: tf.keras.Model = user_model
self.task: tf.keras.layers.Layer = retrieval_task
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
user_embeddings = self.user_model(features['user_id'])
positive_movie_embeddings = self.movie_model(features['movie_title'])
return self.task(user_embeddings, positive_movie_embeddings)
retrieval_model = RetrievalModel(user_model, movie_model)
retrieval_model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
retrieval_model.fit(cached_train, epochs=10)
retrieval_model.evaluate(cached_test)Recommendation system stage 2: Ranking
This is the part we’ve been building up to. Similarly to retrieval process, we’ll define a model using user and movie models we defined earlier. Additionally, we’ll need to define a regression model that will learn to output rating score.
But before we start defining the model, we need to setup the ranking task object.
ranking_task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)Now we have everything that we need to define the model. We’ll also go ahead and compile and train it aswell.
class RankingModel(tfrs.models.Model):
def __init__(self, user_model, movie_model):
super().__init__()
self.movie_model: tf.keras.Model = movie_model
self.user_model: tf.keras.Model = user_model
self.task: tf.keras.layers.Layer = ranking_task
self.ratings = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
def call(self, features: Dict[str, tf.Tensor]) -> tf.Tensor:
user_embedding = self.user_model(features['user_id'])
movie_embedding = self.movie_model(features['movie_title'])
return self.ratings(tf.concat([user_embedding, movie_embedding], axis=1))
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
labels = features.pop('user_rating')
rating_predictions = self(features)
return self.task(labels=labels, predictions=rating_predictions)
ranking_model = RankingModel(user_model, movie_model)
ranking_model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
ranking_model.fit(cached_train, epochs=100)
ranking_model.evaluate(cached_test)Demonstrating results
In the following section, we’ll display how the whole system performs. In essence, we built a short pipeline where results from retrieval model serve as input for ranking model.
user = 42
index = tfrs.layers.factorized_top_k.BruteForce(retrieval_model.user_model)
index.index_from_dataset(
tf.data.Dataset.zip(movies.batch(100), movies.batch(100).map(retrieval_model.movie_model))
)
_, titles = index(tf.constant([f'{user}']))
retrieved = np.asarray(titles[0, :10])
print(f'Recommendations for user with id: {user}: {retrieved}')
ratings = {}
for movie_title in retrieved:
ratings[movie_title] = ranking_model({
'user_id': np.array([f'{user}']),
'movie_title': np.array([movie_title])
})
print('Ratings:')
for title, score in sorted(ratings.items(), key=lambda x: x[1], reverse=True):
print(f'{title}: {score}')Here are the final results.
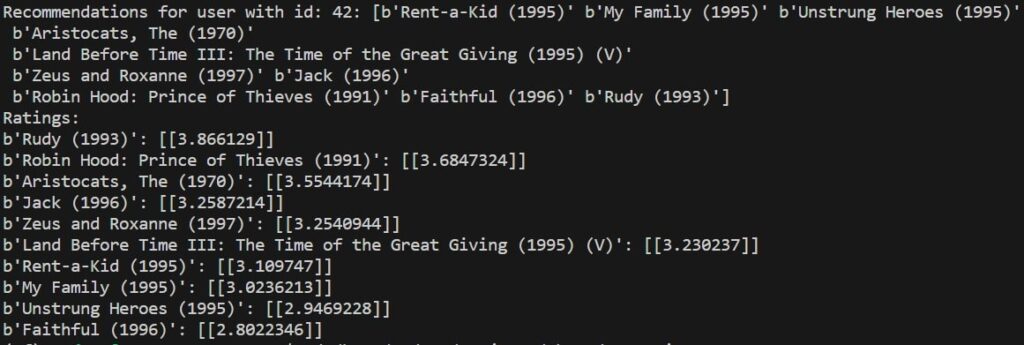
Conclusion
To conclude, we made a simple movie recommendation system including 2 stages. Furthermore, this process shows, how recommendation algorithms usually work, where it first retrieves most relevant objects and then ranks them.
I hope this guide helped you gain a better understanding about them and perhaps motivate you to learn even more.



